In de wereld van softwareontwikkeling vinden een aantal fundamentele verschuivingen plaats door de opleving van verschillende AI-technieken. De belangrijkste impact komt in de vorm van Machine Learning en meer specifiek, een subcategorie van ML genaamd Deep Learning. ML is simpelweg een vorm van AI die een systeem in staat stelt om te "leren" of "getraind" te worden op basis van gegevens in plaats van door expliciet te programmeren. Het is belangrijk op te merken dat deze technieken niet nieuw zijn. De term AI werd voor het eerst bedacht door John McCarthy in 1956 en wordt gedefinieerd als het vermogen van een machine om intelligent menselijk gedrag te imiteren. Dit moet niet verward worden met een machine die intelligentie heeft of in staat is om een mens na te bootsen. AI-systemen zijn ontworpen om specifieke menselijke vaardigheden na te bootsen. Bijvoorbeeld: taal begrijpen, specifieke problemen oplossen, geluiden/beelden herkennen en categoriseren, voorspellingen doen, enz. Dit zijn stuk voor stuk zeer krachtige vermogens, maar ze weerspiegelen geen "echte" intelligentie.
Er zijn in de loop der jaren verschillende soorten AI onderzocht en de meeste zijn in onbruik geraakt, terwijl machine learning zijn renaissance heeft gevonden. In de jaren 90 waren ML en expertsystemen de twee subcategorieën van AI waar het meeste onderzoek naar werd gedaan. Expertsystemen zijn een techniek waarbij een systeem wordt geprogrammeerd met een set regels in plaats van dat het expliciet wordt gecodeerd. De regels werden verwerkt door een "rules/inference engine" en konden worden opgeschaald tot tienduizenden gebeurtenissen per seconde, zelfs op bescheiden hardware. Het probleem was dat de eigenlijke regels nog steeds moesten worden gedefinieerd door materiedeskundigen en beperkt werden door het vermogen van de KMO om alle mogelijke situaties te achterhalen. In werkelijkheid is dit geen AI, maar een benadering ervan.
Machine Learning daarentegen is een techniek waarbij de software (het model) leert van gegevens in plaats van te worden gecreëerd/gecodeerd of gedefinieerd door softwareontwikkelaars. De specifieke ML techniek die ik in dit document beschrijf staat bekend als Deep Learning of Neurale Netwerken. Ik wil erop wijzen dat deze techniek NIET nieuw is en oorspronkelijk al in de jaren 60, 70 en 80 werd ontwikkeld. In feite werd de doorbraak die neurale netwerken bruikbaar maakte back propagation genoemd en ontdekt/gepubliceerd in 1986. Helaas, hoewel de fundamentele technieken om neurale netwerken te implementeren goed bekend waren, waren ze toen niet echt bruikbaar vanwege de enorme verwerkingscapaciteit en datasets die nodig waren om de netwerken te trainen. De enige commerciële oplossing die ik kan bedenken was een product van Computer Associates in de jaren 90, Neugents genaamd (onderdeel van hun systeembeheerpakket). Neurale netwerken werden verlaten door de commerciële sector en het grootste deel van de academische wereld, met slechts een paar universiteiten die onderzoek blijven doen op dit gebied; voornamelijk hier in Canada.
Terug naar Neurale Netwerken die eigenlijk helemaal niet zo ingewikkeld zijn.
Beginnend bij de basis, is een Neuraal Netwerk een verzameling neuronen die met elkaar verbonden zijn in trapsgewijze lagen. Het netwerk begint met een inputlaag, gaat door verborgen lagen en de resultaten gaan uiteindelijk door de outputlaag. Voordat ik in de details van deze structuur duik, moeten we beginnen met wat we bedoelen met een neuron (we bedoelen niet een echte levende cel).
Een neuron is een rekenelement dat meerdere inputs neemt en een enkele output berekent. Hier is een eenvoudig voorbeeld:
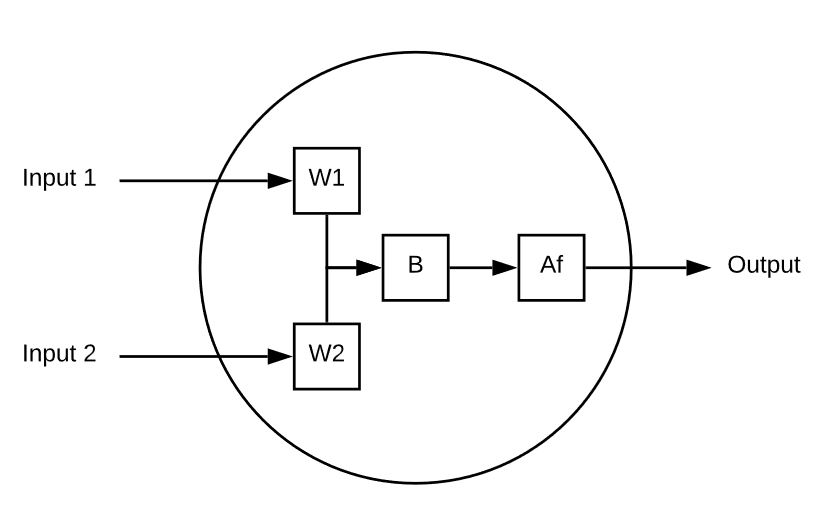
Dit neuron heeft 2 ingangen.
Elke ingang wordt vermenigvuldigd met een gewicht.
De gewogen ingangen worden vervolgens opgeteld en daar wordt een biaswaarde aan toegevoegd.
Ten slotte wordt de niet-grenswaarde door een activeringsfunctie (bijvoorbeeld sigmoïde) gehaald om deze te reduceren tot een voorspelbaar bereik (bijvoorbeeld 0 tot 1).
Hier is een voorbeeld van een enkel neuron in actie:
Ingang 1 = 5, Ingang 2 = 8, W1 = 1 en W2 = .5, uiteindelijk is onze Bias 3
Onze output ziet er als volgt uit
Af( ( 5 * 1 ) + ( 8 * .5 ) + 3 )
Af( 12 ) = 0,999
Laten we het nog eens proberen met een andere set ingangen, gewichten en bias:
Ingang 1 =-10, Ingang 2 = 10, W1 = 0,2, W2 = 0,1, Bias = 0,5
Uitvoer = Af( (-10 + 0.2) + ( 2 X 0.1) + 0.5)
Uitgang = Af( -8.1 ) = 3.034
Een enkel neuron op zichzelf is in wezen nutteloos, behalve als een interessante wiskundeoefening, maar als we meerdere neuronen samenvoegen in lagen kunnen we een neuraal netwerk krijgen in de vorm van:
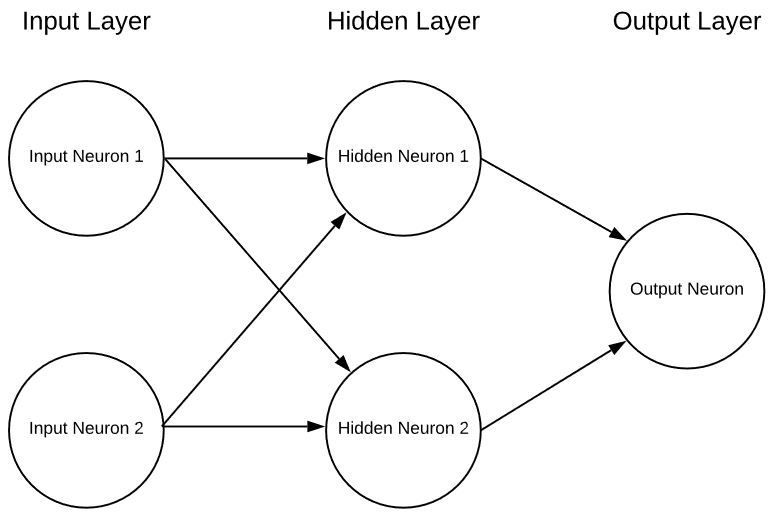
Dit is een extreem simplistisch neuraal net met 2 ingangen, een enkele verborgen laag neuronen en tot slot een enkel uitgangsneuron. Neurale netten kunnen een willekeurig aantal ingangen, lagen en een willekeurig aantal neuronen in die lagen hebben. Deze flexibiliteit is het enige serieuze probleem met neurale netwerken. Hoe weet de ontwerper van het netwerk wat het optimale aantal lagen en neuronen in die lagen is? Er zijn een aantal richtlijnen waar je moet beginnen, maar de realiteit is dat je dit met vallen en opstaan moet uitzoeken. Momenteel wordt er veel veelbelovend onderzoek gedaan om hierbij te helpen, maar we zijn nog maar net begonnen om dit uit te zoeken.
Dus hoe kies je de juiste gewichten en biases voor elk neuron en hoe "leert" het?
Geweldig onderwerp voor de volgende aflevering.